Erróneamente en ocasiones se piensa que el trabajo del analista es abrir la base de datos y ale, a usar esas técnicas chachi y modelos potentes que te mueres de ganas de usar. Nada más lejos de la realidad. Yo calculo que el 90% de mi trabajo de análisis es tener una base de datos apta para poder aplicar esos modelos. Normalmente encuentras que has metido valores imposibles (usad filtros en vuestra hoja de cálculo al meter los datos!!!), valores perdidos codificados de manera confusa (si varios metéis datos, acordad unas pautas y normas!) o etiquetas con pequeños errores (ídem e ibídem). No son todos los problemas que existen, pero sí son de los que me apetece escribir (:P). Como siempre, si os interesa algo más, escribidme.
Pues hoy vamos a ver algunos pasos para hacer que nuestra base de datos ses analizable. Primero de todo, cargamos paquetes y abrimos la base de datos. La base de datos me la he inventado yo para ilustrar este tutorial. Muchos diréis -con razón- que para un archivo con 50 líneas y 5 columnas, pero la idea es aprender para cuando el archivo tiene un tamaño impracticable. La podéis encontrar aquí
Primer paso es poner los paquetes que necesitamos. Si hacéis como yo y trabajáis con diferentes ordenadores, este código os irá bien porque se ocupará de instalar y cargar los paquetes si no están instalados. Eso sí, a la hora de compartir código, tenéis que advertir que esa línea instalará cosas. Para abrir los datos usaremos fread() y le especificaremos un ‘encoding’. De esta manera nos aseguramos que nuestraws Ñ se queden en forma Ñ y no de una ristra extraña de símbolos.
if (!require("pacman")) install.packages("pacman") # esto nos intala pacman, un paquete gestor de paquetes## Loading required package: pacmanpacman::p_load("data.table", # con fread() nos abrirá los archivos csv rápido.
"tidyverse", # indispensable <2
"tidylog", # Nos dirá que va pasando con nuestros datos
"naniar", # valores perdidos
"visdat", # visualizar la base de datos
"summarytools", # para... pues para eso
"janitor") # para dejar limpitos los datos
df <- fread("../../fake_messy_data.csv", encoding = "UTF-8")
df %>% glimpse()## Rows: 50
## Columns: 5
## $ id <chr> "A1", "A2", "A3", "A4", "A5", "A6", "A7", "A...
## $ edad <int> 21, 22, 333, 89, 90, 45, 65, 34, 23, 21, 19,...
## $ `LETRA FAVORITA` <chr> "a", "B", "C", "D", "c", "d", "c", "a", "b",...
## $ humor <chr> "bueno", "bueno", "bueno", "bueno", "malo", ...
## $ `calida de su letra ñ` <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 1, 1, 2, 3, 4, 5,...Lo primero que podemos es observar es… columnas con nombres raros. El infierno (aunque hay infiernos peores, lo sabéis) con carácteres especiales, espacios, mayúsculas… Vamos a cargarnoslos con janitor::clean_names() y renombrarlos a algo más fácil de manejar con dplyr::mutate(). Como veréis si ejecutáis el código, tidylog os imprime en rojo si hay cambios en la base de datos.
df <- df %>% clean_names()
# de esta forma los espacios se convierten en barras bajas, los carácteres especiales se quitan y todo
# pasa a minúsculas. Luego haremos lo mismo con una variable.
colnames(df)## [1] "id" "edad" "letra_favorita"
## [4] "humor" "calida_de_su_letra_n"df <- df %>% mutate(letra = letra_favorita, calidad = calida_de_su_letra_n) ## mutate: new variable 'letra' (character) with 10 unique values and 0% NA## new variable 'calidad' (integer) with 10 unique values and 2% NAAhora queremos ver que hay aquí… para ello usaremos diferentes funciones.
df %>% visdat::vis_dat()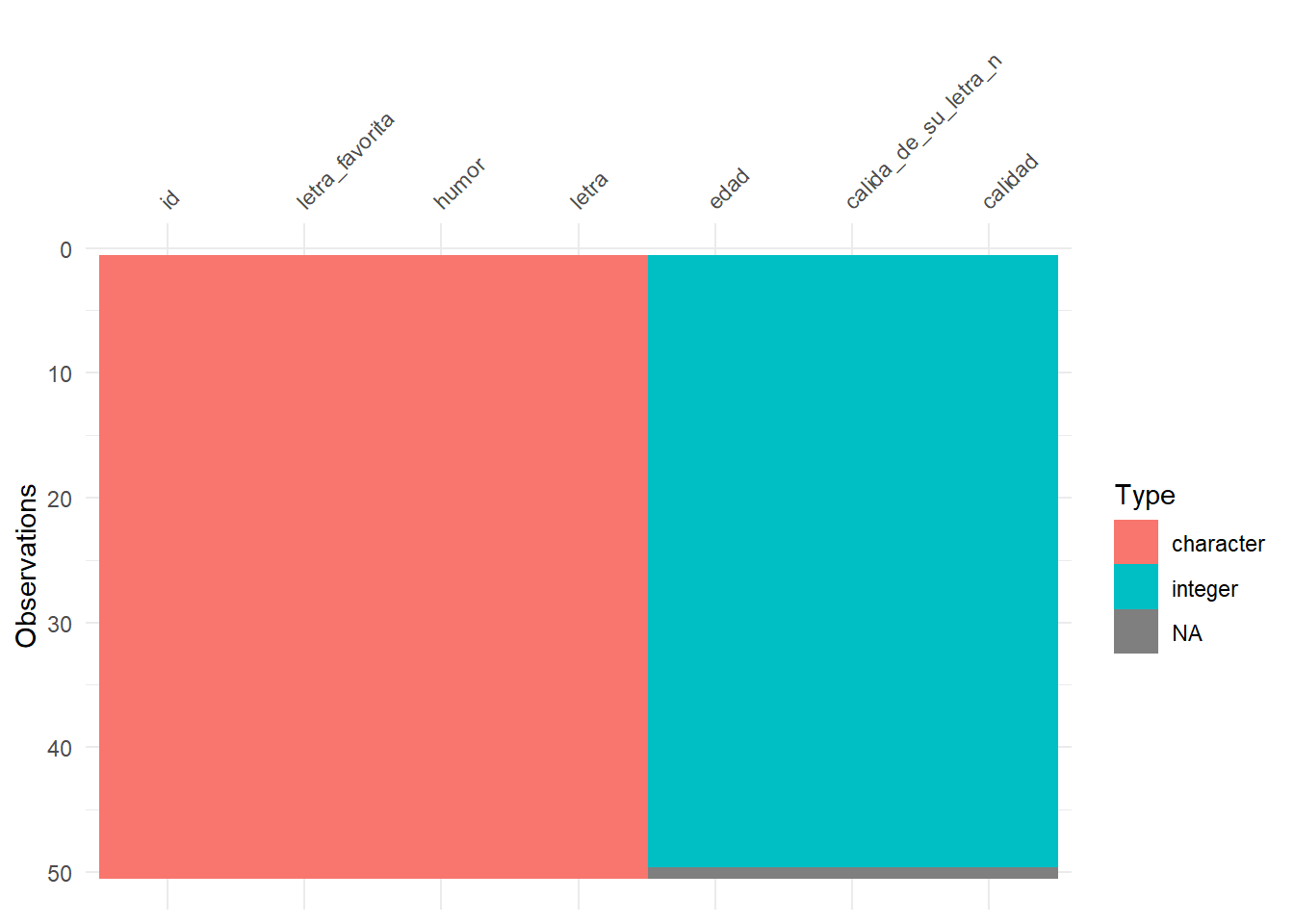
Lo que tenemos aquí es que parece que hay varias columnas con contenido de tipo ‘character’ y algunas numéricas (integer) junto a un participante con valores perdidos (NA). A simple vista parece que todo va bien. Sin embargo… cuando vemos en detalle…
dfSummary(df)## Data Frame Summary
## df
## Dimensions: 50 x 7
## Duplicates: 0
##
## ------------------------------------------------------------------------------------------------------------------
## No Variable Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- ----------------------- -------------------------- -------------------- ------------------ -------- ---------
## 1 id 1. A1 1 ( 2.0%) 50 0
## [character] 2. A10 1 ( 2.0%) (100%) (0%)
## 3. A11 1 ( 2.0%)
## 4. A12 1 ( 2.0%)
## 5. A13 1 ( 2.0%)
## 6. A14 1 ( 2.0%)
## 7. A15 1 ( 2.0%)
## 8. A16 1 ( 2.0%)
## 9. A17 1 ( 2.0%)
## 10. A18 1 ( 2.0%)
## [ 40 others ] 40 (80.0%) IIIIIIIIIIIIIIII
##
## 2 edad Mean (sd) : 49.3 (47.8) 13 distinct values : 49 1
## [integer] min < med < max: : (98%) (2%)
## 19 < 34 < 333 :
## IQR (CV) : 42 (1) : .
## : :
##
## 3 letra_favorita 1. (Empty string) 1 ( 2.0%) 50 0
## [character] 2. 99 4 ( 8.0%) I (100%) (0%)
## 3. a 9 (18.0%) III
## 4. b 5 (10.0%) II
## 5. B 8 (16.0%) III
## 6. c 9 (18.0%) III
## 7. C 4 ( 8.0%) I
## 8. d 5 (10.0%) II
## 9. D 4 ( 8.0%) I
## 10. r 1 ( 2.0%)
##
## 4 humor 1. (Empty string) 1 ( 2.0%) 50 0
## [character] 2. bueno 15 (30.0%) IIIIII (100%) (0%)
## 3. Bueno 1 ( 2.0%)
## 4. buero 1 ( 2.0%)
## 5. mako 1 ( 2.0%)
## 6. malo 30 (60.0%) IIIIIIIIIIII
## 7. Malo 1 ( 2.0%)
##
## 5 calida_de_su_letra_n Mean (sd) : 4.7 (2.7) 1 : 9 (18.4%) III 49 1
## [integer] min < med < max: 2 : 5 (10.2%) II (98%) (2%)
## 1 < 5 < 9 3 : 5 (10.2%) II
## IQR (CV) : 5 (0.6) 4 : 5 (10.2%) II
## 5 : 5 (10.2%) II
## 6 : 5 (10.2%) II
## 7 : 5 (10.2%) II
## 8 : 5 (10.2%) II
## 9 : 5 (10.2%) II
##
## 6 letra 1. (Empty string) 1 ( 2.0%) 50 0
## [character] 2. 99 4 ( 8.0%) I (100%) (0%)
## 3. a 9 (18.0%) III
## 4. b 5 (10.0%) II
## 5. B 8 (16.0%) III
## 6. c 9 (18.0%) III
## 7. C 4 ( 8.0%) I
## 8. d 5 (10.0%) II
## 9. D 4 ( 8.0%) I
## 10. r 1 ( 2.0%)
##
## 7 calidad Mean (sd) : 4.7 (2.7) 1 : 9 (18.4%) III 49 1
## [integer] min < med < max: 2 : 5 (10.2%) II (98%) (2%)
## 1 < 5 < 9 3 : 5 (10.2%) II
## IQR (CV) : 5 (0.6) 4 : 5 (10.2%) II
## 5 : 5 (10.2%) II
## 6 : 5 (10.2%) II
## 7 : 5 (10.2%) II
## 8 : 5 (10.2%) II
## 9 : 5 (10.2%) II
## ------------------------------------------------------------------------------------------------------------------El horror acecha. La única columna que parece estar bien es “id” puesto que muestra 50 valores únicos que coinciden con nuestros 50 casos. La edad muestra un máximo de 333…y la letra favorita… bueno. Ahí está el caos. Tenemos un valor perdido mal codificado como 99, letras en mayúscula y minúscula (d y D) y además tenemos una letra que no concuerda con el resto (r). La estrategia que seguiremos es primero de todo marcar el valor perdido como NA y luego limpiar los datos con janitor.
# con esta funcion del paquete naniar podremos cambiar en todo el archivo el 99 por NA
df <- df %>% na_if("99")
# Con estas dos funcione del paquete stringr convertiremos en minuscula (str_to_lower) y
# qiutaremos los espacios (str_trim). Que en este caso no hay espacios, pero nunca está demás
# tenerlo como costumbre
df. <- df %>% mutate(letra_favorita = str_trim(str_to_lower(letra_favorita))) ## mutate: changed 16 values (32%) of 'letra_favorita' (0 new NA)Bien, nuestra columan letra_favorita est´´a casi lista. Aun nos falta un detalle. Queda esa “r”. Tras consultar los cuestionarios de donde tomé esta información me doy cuenta que la r es una a. ¿Qué hago? Podría cambiarlo a mano, pero aquí queremos aprender cosas generalizables : ) Vamos a usar una función que siempre tengo que mirar en la guía (como pivot_longer…) y es case_when. Esta función cambiará un valor por otro. Algunos me diréis que ifelse() podemos conseguir lo mismo, pero, cuando tengamos 10 valores que cambiar, ifelse será confuso. Vamos allá.
df <- df %>% mutate(letra_favorita = case_when(
letra_favorita == "r" ~ "a",
TRUE ~ as.character(letra_favorita)
))## mutate: changed one value (2%) of 'letra_favorita' (0 new NA)Seguramente os preguntéis como funciona el tal case_when… Funciona cambiando el valor según unas reglas. Hay una parte de evaluación a la izquierda y una parte de cambio a la derecha (después del ~ ). Es decir, lo que hace es cambiar el valor del que cumpla una condición (en este caso que la letra sea “r” y lo cambia por lo que está después de la tilde ~, en este caso, “r”). ¿Y que pinta el TRUE ~ as.character(letra_favorita)? Es una código mágico. Místicamente mantendrá igual a los que no cumplan la condicion de equivaler a “r”. En otras ocasiones querremos cambiar los casos que no lo cumplen…. Como veis será útil para otras cosas que veremos en próximos posts.
Como ejercicio, está la columna humor con problemas parecidos. ¡Toda vuestra!
En esta sesión hemos visto como adecuar una columna, pero quedan otras. Por ejemplo, la de edad que tiene un valor imposible y hay un participante del que no tenemos datos. A la hora de manejarnos con una base de datos con problemas es que tendremos que tomar decisiones que afectarán al análisis. ¿elimino al participante con edad imposible?¿Le cambio la edad por NA?¿Sustituyo los valores perdidos?¿Debo filtrar así las variables? La parte positiva de realizar estos cambios con R es que nuestras decisiones son trazables, reproducibles y… mutables. Por lo que si algo no nos convence o nos hemos equivocado, cambiamos nuestros código y ya. . En un futuro hablaremos de la columna numérica calidad inspirándome en untuit..